Introduction
In this age of the internet and ease of travel, we are spoilt for choice when it comes to picking a restaurant to dine at. Normally, we look at the rating given to the restaurant on Yelp and pick the one with the highest rating. However, this rating does not take into account the user's own preferences. For example, if the user dislikes seafood, a restaurant with a high rating due to the quality of its fish meals is not the correct choice for the user to pick. So if we can incorporate the biases of the user and predict a star rating using these biases as a prior, we would be able to offer a better selection of restaurants to choose from. We aim to virtually send the user to the restaurant and then predict the star rating and text review which the user would've written for the particular restaurant. The user can look at the most likely result if he goes to this restaurant and take into account both: the rating and the review, to make a better decision. Additionally, a person usually goes to restaurants with friends who share similar culinary tastes. Incorporating the user's friends as additional priors will enable even better recommendations.
Preprocessing
The preprocessing was done using pandas. We used the reviews.json file for getting attributes like review_id, user_id, business_id, and stars. Additionally, we merged this file with the data from user.json to get a final data frame that has the following attributes: review_id, user_id, business_id, friends, stars. This data frame was then used to implement the standard latent-factor and improved latent factor models. For language modeling, the restaurant reviews were filtered out from all user reviews.
Analyzing the dataset
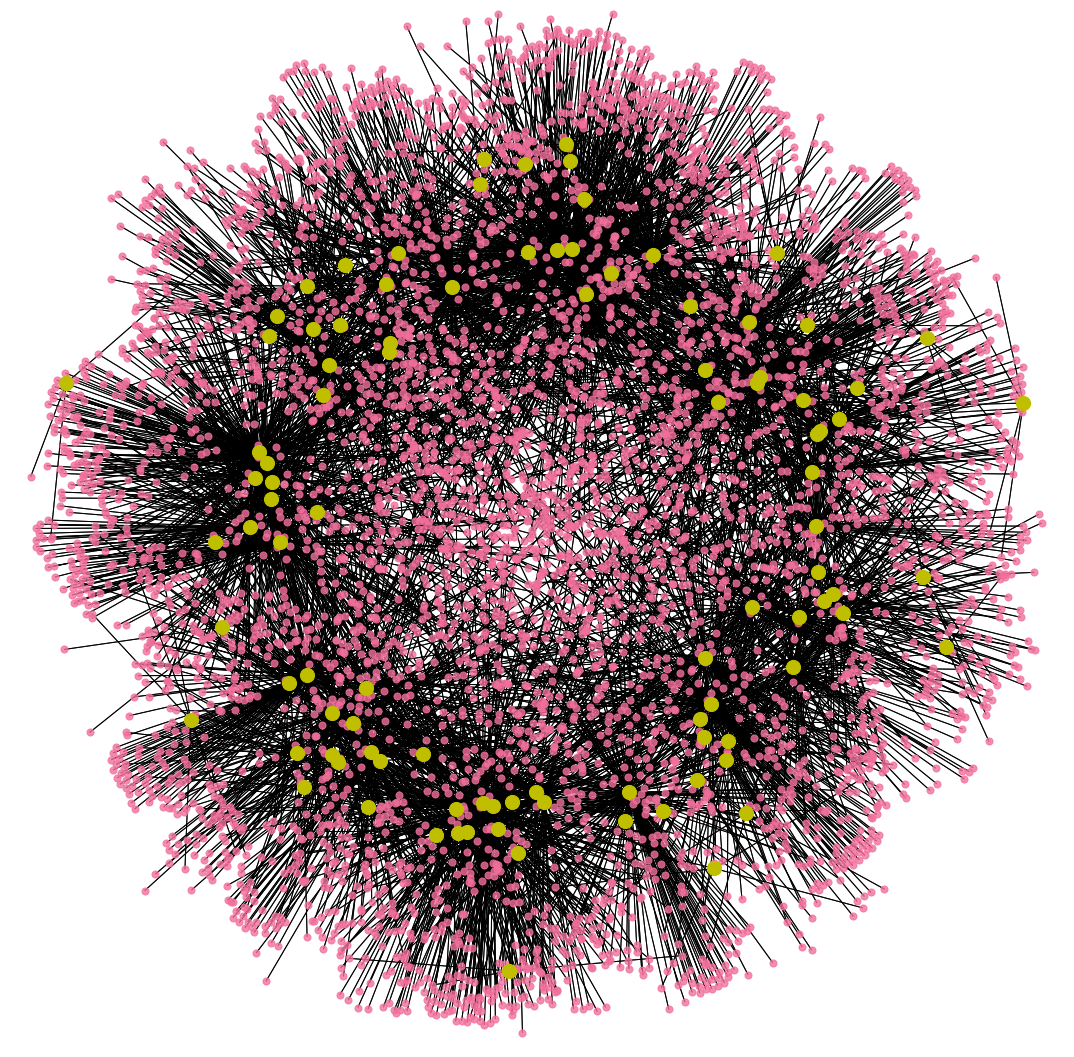

The dataset that we are working with is the Yelp Open Dataset. It contains data of businesses, users, reviews, photos, check-ins and tips. For the purpose of our project, we are using the business, review and user data. These include 6,685,900 reviews; 192,609 businesses and 1,637,148 users. Of the 192,609 businesses spanning various categories, we are using the data of 59,371 restaurants and their 5,763,938 reviews. For predicting user ratings and creating recommendations, we are using the data of 37,619 restaurants; 504,870 users and 1,000,000 ratings. To fine-tune the language model for review generation, we are using 1,000,000 restaurant reviews. The user-friend network above was created by randomly picking 100 users from a pool of 791,064 users having more than 2 friends. Two nodes are connected by an edge if they are friends. The graph also contains mutual friend information in the form of cycles in the graph. The pie-chart above shows the distribution of ratings among 5,763,938 reviews. We observe that 4 and 5 star ratings dominate.
Recommender System
Approach:To generate the star rating we use a standard latent factor model and train the weight values using stochastic gradient descent in a supervised manner. The user's friends who have gone to the same restaurant are added as a separate set of weights.
Latent Factor models:
Latent Factor models are a state-of-the-art methodology for model-based collaborative filtering. The basic assumption is that there exists an unknown low-dimensional representation of users and items where user-item affinity can be modeled accurately. In the yelp dataset, the rating that a user gives to a restaurant is assumed to depend on multiple implicit factors such as the user’s tastes and the biases users have towards a particular restaurant. We want to use these biases to accurately predict the rating a user will give.
Model:
The model consists of multiple latent factors that each represent different aspects that the model is expected to capture.
$$s_{u,r} = \alpha + \beta_u\ +\ \beta_r\ + \gamma_u^T\gamma_r$$ $$\Theta=(\alpha,\beta_u,\beta_r,\gamma_u,\gamma_r)$$ $\alpha$ -> mean star rating of every review
$\beta_u$-> bias scalar value for each user
$\beta_r$-> bias scalar value for each restaurant
$\gamma_u$-> k-dimensional weight vector for each user which be multiplied with the weight vector for restaurant
$\gamma_r$-> k-dimensional weight vector for each restaurant which be multiplied with the weight vector for user
We will now break-down each term in the rating equation.
Baseline Recommendation:
In the term ($\alpha + \beta_u + \beta_r$), $\beta_u$ and $\beta_r$ represent the observed deviations of ratings of user $u$ and restaurant $r$ repsepectively, from the average rating.
SVD:
Matrix factorization models map both users and items to a joint latent factor space of dimensionality $k$, such that the user-restaurant interactions are modeled as inner products in that space. The latent space attempts to explain ratings by characterizing features that might relate to obvious aspects like type of food and time of service to less obvious aspects such as "uniqueness" in terms of food and atmosphere. Accordingly, each restaurant $r$ is associated with a vector $\gamma_r\in\mathbb{R}^k$ and each user is associated with a vector $\gamma_u\in\mathbb{R}^k$. For a given restaurant $r$, the elements of $\gamma_r$ represent the amount of each feature that the restaurant possesses and the corresponding elements in $\gamma_u$ represent the degree to which the user values each of those features. The resulting dot product $\gamma_u^T\gamma_r$ captures the interaction between the user $u$ and restaurant $r$ and characterizes the overall interest of the user in the restaurant.
We also want to include the factor of a user's friends into the rating prediction. When the friend factor is included, the equations change to:
$$s_{u,r} = \alpha + \beta_u\ +\ \beta_r\ + \left(\gamma_u + \frac{1}{\sqrt{|F_{u,r}|}}\sum_{i\in F_{u,r}}f_i \right)^T\gamma_r$$ $$\Theta=(\alpha,\beta_u,\beta_r,\gamma_u,\gamma_r, F_{u,r})$$
Where $F_{u,r}$ represents the friends of user $u$ who have also visited and rated restaurant $r$,
$y_f$ : k-dimensional vector for each friend which represents friend $f$ who has also visited the restaurant $r$.
Friends term:
To each user $\gamma_u$ we add an additional set of friend factors for that restaurant which will influence the user's overall interest in the restaurant. Each of the terms $f_i$ from $|F_{u,r}|$ represents a unique friend's influence on the user given that they have visited restaurant $r$ already. Since the $f_j$'s are centered around 0 due to the regularization term, the sum of these terms is normalized by $|F_{u,r}|^{-1/2}$ in order to stabilize the variance across the range of observed values.
Initialization:
$\alpha$ is initialized to average star rating over all reviews.
$\beta$ for both user and restaurant are initialized to average star rating.
$\gamma$ is initialized to a random value between $0$ and $\sqrt{5/k}$ so that the product of the two values remains between 0 and 5.
$y_f$ is intialized to all zeros.
Training:
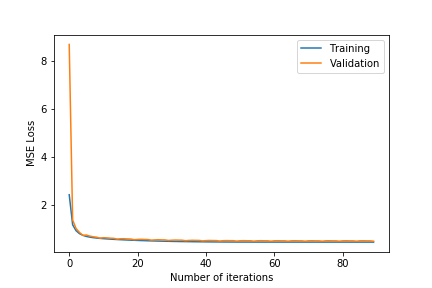
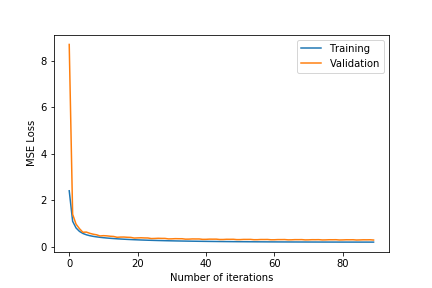
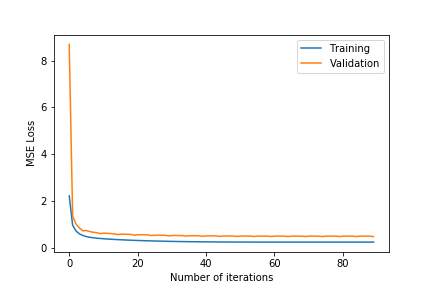
The entire dataset has 1 million reviews. This set is randomly split into the test and training set, where the test set consists of 200,000 reviews and the training set consists of 800,000 reviews. We run the entire training set through stochastic gradient descent for 100 iterations. During training we use 5-fold Cross Validation and calculate both the training error and validation error across iterations. The size of the training set for each iteration of cross validation is 640,000 and the size of the validation set is 160,000. We test different hyperparameters for different regularization ($\lambda$), learning rate ($\eta$) and number of dimensions ($k$) and pick the combination that gives us the lowest MSE on the test dataset.
$$\text{Mean Square Error Loss} =\underset{\Theta}{argmin}\frac{1}{|\tau|} \sum_{s_{u,r}\in\tau} (\hat s_{u,r} - s_{i,j})+ \lambda\Omega(\Theta)$$ Where $\Omega$ represents the $l_2$ norm and $\lambda$ is the regularizer used to penalize complex models.
Update equations for gradient descent:
$\text{Error},\ e_{u,r} = (\hat s_{u,r} - s_{i,j})$
$\beta_u=\beta_u \ +\ \frac{\eta}{2}\left(2e_{u,r}-\lambda\beta_u\right)$
$\beta_r=\beta_r \ +\frac{\eta}{2}\left(2e_{u,r}-\lambda\beta_r\right)$
$\gamma_u=\gamma_u \ +\frac{\eta}{2}\left(2e_{u,r}\gamma_r-\lambda\gamma_u\right)$
$\gamma_r=\gamma_r \ +\frac{\eta}{2}\left(-\lambda\gamma_r+2e_{u,r}(\gamma_u + \frac{1}{\sqrt{|F_{u,r}|}}\sum_{i\in F_{u,r}}f_i) \right)$
$f_j = f_j +\frac{\eta}{2}\left(-\lambda f_j+2e_{u,r}\frac{1}{\sqrt{|F_{u,r}|}}\gamma_r\right)$
Testing:
We use the trained parameters in $\Theta$ and predict the rating given a user and a business from the test dataset. We use MSE and output the resulting error.
Experimental analysis:
| k = 75 | k = 100 | |
|---|---|---|
| $\lambda=$ 0.2 | 1.9643 | 1.8634 |
| $\lambda=$ 0.4 | 1.70816 | 1.6832 |
| $\lambda=$ 0.6 | 1.9849 | 1.9843 |
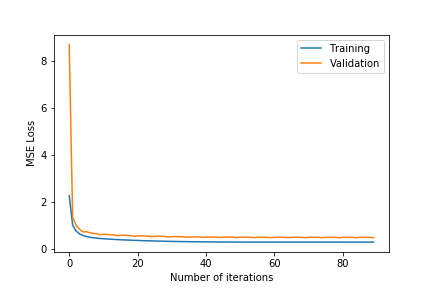
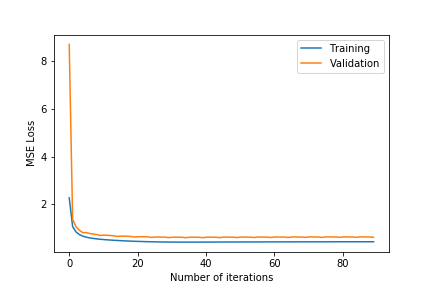
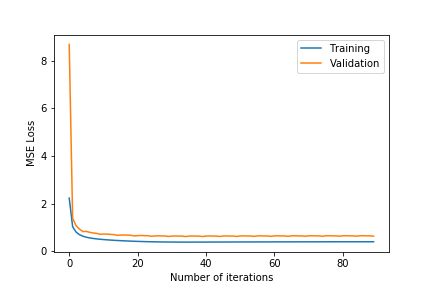
| k = 75 | k = 100 | |
|---|---|---|
| $\lambda=$ 0.2 | 1.97105 | 1.866 |
| $\lambda=$ 0.4 | 1.8742 | 1.82045 |
| $\lambda=$ 0.6 | 2.01119 | 2.0012 |
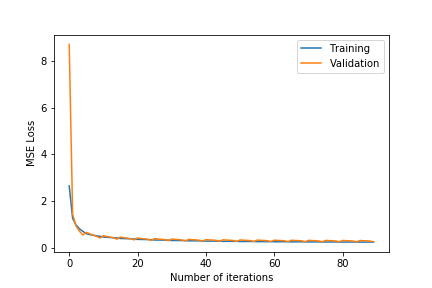
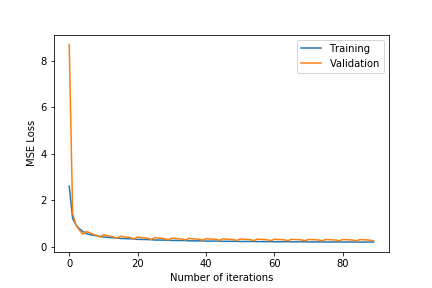
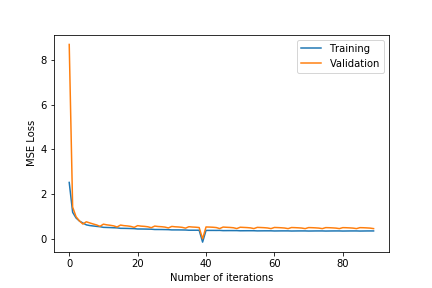
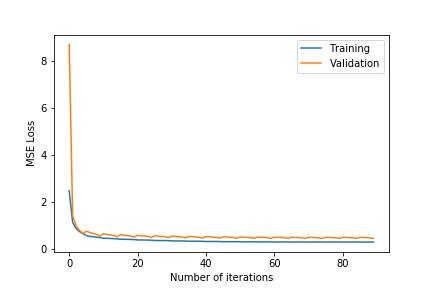
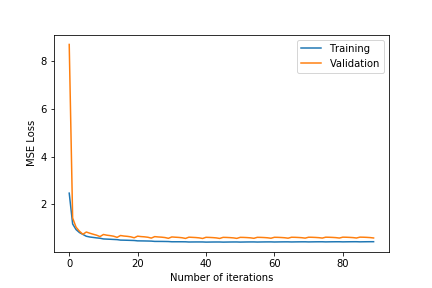
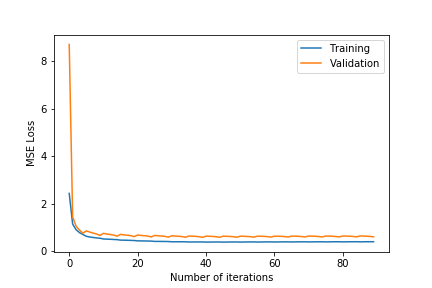
- $\lambda\in${$0.2,0.4,0.6$}
- $k\in${$75,100$}
- Observing the plots, we notice that a higher value of $k$ as 100 will always give a training error curve closer to the validation error curve. The test error also reflects this observation as the, higher number of dimensions always equates to lower test error. We also tested for more than 100 and less than 75 and these gave worse results so we haven’t included these.
- $\lambda =0.4$ gives the best results. $\lambda =0.6$ results in underfitting the data far too much as the test error is comparatively very high. $\lambda =0.2$ results in overfitting the training data as although the training error is close to the validation error, the test error is comparatively much higher.
- The test error for all the different hyper-parameter combinations decreases when we include the friend term indicating that including the user’s friends as an additional factor is making a noticeable positive difference.
- The best test error of 1.683201 occurs for $\lambda=0.4$ and $k=100$.
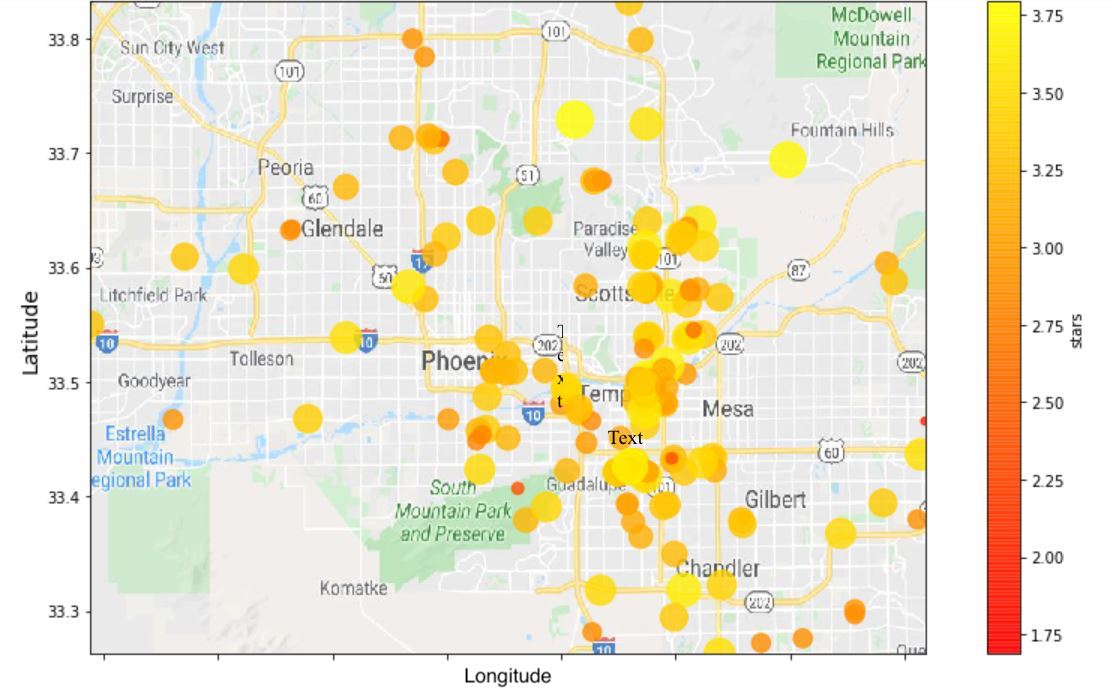
Heat Map of Recommendations
The heat map represents the predicted ratings of a user given 246 possible restaurants in their immediate area. All the ratings were predicted using the best model. The higher the rating according to the heat map label, the more likely the user would like going to that particular restaurant.
Language Modeling
Although natural language follows some rules, it also contains numerous exceptions that create ambiguities. We, as humans are able to understand its usage, but the lack of a formal specification makes language modeling a complex task. An alternate approach to this task is to learn from examples. Statistical language modeling aims to determine the probability of a sequence of words. It can be used to predict the next word in a given sequence. For our project, two state-of-the-art models were evaluated: XLNet and GPT-2.
GPT-2
GPT-2 is an unsupervised pre-trained language model that was developed by OpenAI and can be used for text generation. The largest model contains 1.5 billion parameters and was trained on 8 million web pages. GPT-2 presents a wide variety of capabilities, including the ability to generate conditional synthetic text samples of unrivaled quality, where we prime the model with an input and use it to generate a lengthy continuation. GPT-2 outperforms models trained on specific domains without being trained on these domains. GPT-2 is based on the Transformer, which is an attention model - it learns to focus attention on the previous words that are the most relevant to predict the next word in the sentence. This model uses attention to boost the speed with which deep learning models can be trained. The 117M model used in our project consists of 12 layers, with 12 distinct attention patterns in each layer.
Let's see how GPT-2 finishes a sentence beginning with "The litter box":
The litter box.
Not only is it a waste of money, but it's also a waste of time and space. Not only do you have to take your dog out of the house every time he goes outside, but you also have to deal with the litter box when you come home.
Now we generate a sentence beginning with "The lunch box":
The lunch box also came with a box of cookies and a cookie jar.
- We can observe that the model seems to understand that a lunch box is different from a litter box.
- It focuses on the head of the phrase, in our case, "litter" or "lunch", when predicting the next word in the sentence. This is one of the 144 attention patterns available in GPT-2.
- The attention-based model enables GPT-2 to adapt to the style and content of prefix, generating realistic and coherent continuations.
XLNet
XLNet employs generalized permutation language modeling, which predicts the probability of any sequence using any permutation in an auto regressive fashion. It makes use of the Transformer architecture and introduces a novel two-stream attention mechanism to achieve the same.
GPT-2 vs XLNet
GPT-2 can assign a probability to any sequence of characters while XLNet has limited vocabulary and doesn’t handle multilingual characters or emojis. While GPT-2 models the text from left to right, XLNet can model in any possible permutation. New line characters can only be generated by the GPT-2 model. Taking all these factors into consideration, GPT-2 seems to be the better choice and remains the most accurate generation model.
Let us compare the text generated by the two models using the same prefix “The ambience at the restaurant”. Text generated by XLNet:
The ambience at the restaurant was a bit less than ideal, but it didn’t feel like it was a big production. The server was a rather friendly, and I found that the place was packed to the brim, so it made sense. The room itself was a bit more spacious, but still just that small. The staff was friendly, also quite solid, and definitely nothing I was looking for. The food was nice, and pretty solid. The staff were very supportive, and very solid.
Text generated by GPT-2:
The ambience at the restaurant was simple: simple, but striking. The food, if you could call it that, was basic, but the service was impeccable. Our server, Bob, was friendly, knowledgeable and attentive.
- We can observe that XLNet makes a lot of context-related mistakes: it calls the restaurant a “production”, says the place was packed to the “brim” and calls the staff and food “solid”.
- XLNet also outputs contradictory phrases such as: the staff was friendly but not what it was looking for and that the room was spacious but still small.
- GPT-2, on the other hand, uses appropriate adjectives for the server and outputs semantically correct sentences.
- If one were to guess whether the above reviews were real or fake, the review generated by XLNet would easily be identified as fake and the review generated by GPT-2 would most likely be identified as real.
Review Generation
We chose to use OpenAI’s GPT-2 to generate reviews for restaurants based on the star rating: we generate positive reviews for 5-star ratings and negative reviews for 1-star ratings. For the purpose of this project, the 117M GPT-2 model was fine-tuned using 1,000,000 restaurant reviews using a batch-size of 512. The reviews were filtered based on their star ratings and fed as input to the model. There is also an option of providing a prefix to the model, forcing it to start with the given text.
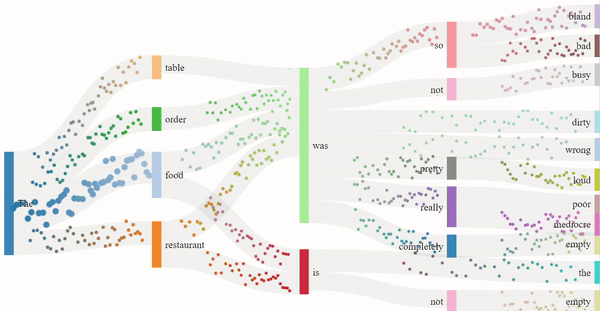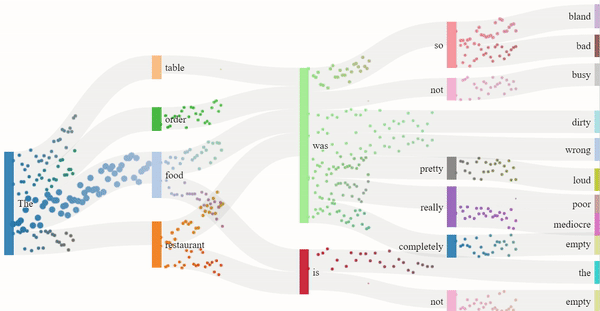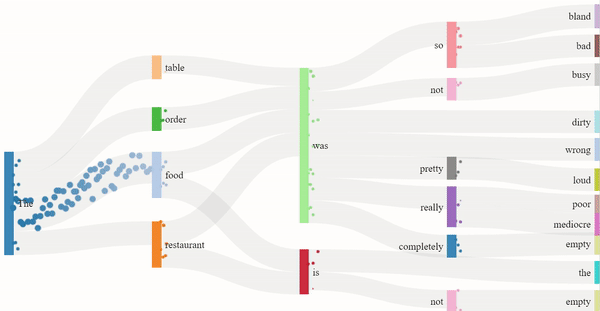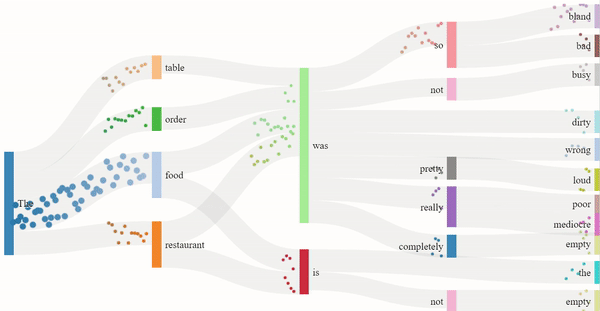
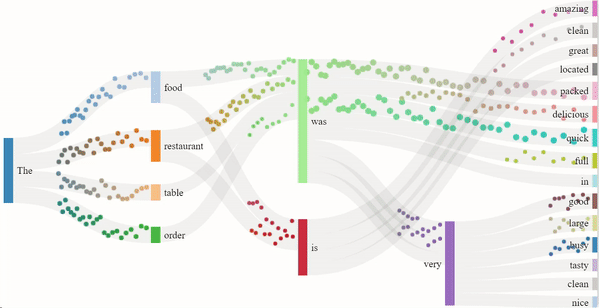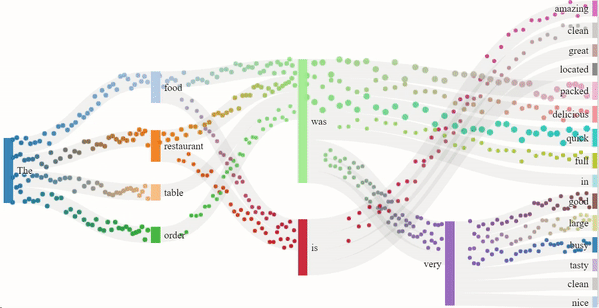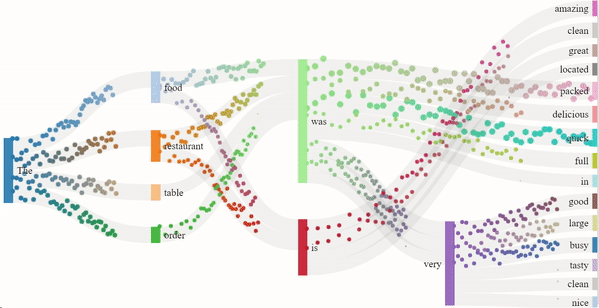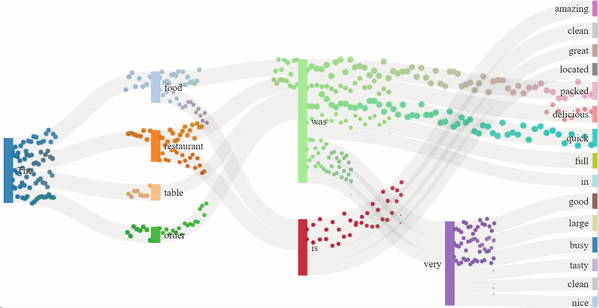
As we read text from left to right, it is the sequence of the words that imposes meaning to the sentence. Similarly, GPT-2 guesses the next word in the sentence based on the previous ones. The flow model for the 1-star and 5-star review generation depicts just that. The dots are split into channels depending on the probability of the next word, more dots indicating a higher probability. The presence of certain nouns such as "food" or "restaurant" acts as an indicator for the model to generate content off of. Hence, the words that follow "food" are "delicious" or similar descriptors, and the words that follow "restaurant" are "clean" or other valid descriptors.
Pre-trained vs Fine-tuned
We compare the output of the pre-trained model against the fine-tuned model which generates more relevant text for restaurant reviews. The pre-trained model (without fine-tuning) generates the following pieces of text with the prefix set to "The food here is":
The food here is limited but better than other supermarkets. The staff are friendly and helpful. They will help you find what you are looking for. They also have a great selection of wine and beer. I have been shopping at Trader Joe's for years and this is the best place to buy the items I need. You can find all kinds of fruits and vegetables, meats, cheese, baked goods, and even vegan items.
The food here is not made with animals. It is made from grass. The chickens are taken out of the cage and fed the meat with the butter. It is very good. This is not a cheap meat. There are some who buy it, some who don't. I find it very difficult to find it on the street. We buy it at supermarkets, but most don't.
2-star reviews generated by the fine-tuned model:
The food here is very average, nothing to write home about. The average one I have is $15 for a small lunch and a small burrito. It's a little more expensive for a lunch, but I guess it gets you started. I ordered the "Sam's Club" taco with guacamole and a small red onion burrito. The guacamole was a little too sweet and tasted like it came straight from the corn tortilla. I ordered a steak burrito with guacamole. The steak tasted like it was cooked in oil and cut in half. It was really dry and chewy. The red onion burrito was ok, but the amount of guacamole was a little too much. It was almost tasteless, and it was really salty.
The food here is a little weird. I ordered the hot pot chicken. I got the chicken and it was not very hot. I think it was just chicken. The sauce was a little weak and the rice was really watery. I would give 4 stars if they could use some heat.
5-star reviews generated by the fine-tuned model:
The food here is always good and the service is always great. The ambiance is great. It's a very cozy place with a very cool vibe. It's a great place for dates. The food is great and you can't beat the variety. I had the Falafel Tacos with Broccoli and the Beef Tacos with Rice. The meats were cooked perfectly and the sauce was perfect. I would definitely come here again.I love this place!! It's not a fancy restaurant but it's fun to see.
The food here is awesome. I had the chicken grill, which came with a large steak and a drink, and I had the chicken Brussels sprouts. I ordered a rack of rib eye, and a couple of my friends ordered a quarter rack of chicken and two different types of entrees. The chicken was amazing, good flavor, and tender. The Brussels sprouts were in a nice crunchy texture, very tender. A friend ordered something called their chicken fingers, and I ordered the chicken fingers. The serving size was perfect. The entrees were nice and delicious. The service was prompt and friendly. I will definitely go back. We had a great meal at the Vegas buffet. The menu was very good. I will definitely be coming back.I stumbled upon this gem by accident while driving by the strip. It was hard to find a place that didn't have a beer. I heard a couple people were coming around the block and it was a perfect spot. Shout out to Chris for the food and the way the owners got to know me so I could see why they were so excited about the place.
- We can observe that the pre-trained model generates text about food but the outputs are not specific to restaurant reviews. The fine-tuned model generates outputs specific to restaurant reviews.
- The 2-star reviews are clearly negative and describe what aspects of the restaurant the customer found unsatisfactory. The second review has a witty comment about the restaurant serving cold food, showing that the model can capture humor.
- The 5-star reviews are extremely positive and describe what the customer liked about the restaurant, such as the food, atmosphere and/or service.
- So, we can see that GPT-2 accurately captures what constitutes a restaurant review, it knows that it must include: general opinions of the customer, what kind of food they had and whether they would recommend the place or not.
Analyzing the Vocabulary
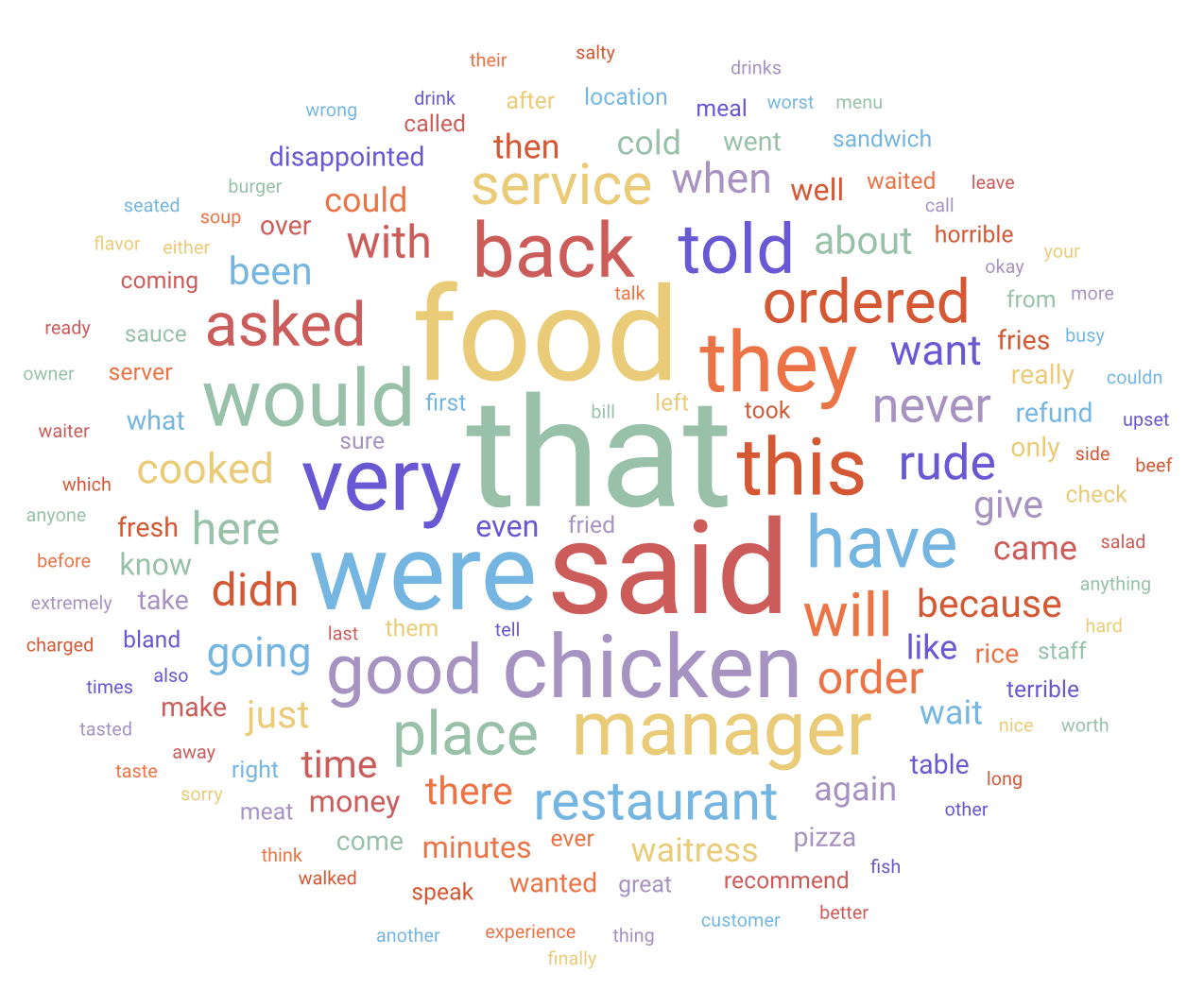

- If we take a close look at the word clouds, we can observe that the food and service are the main focus and are frequently discussed in reviews.
- The 1-star cloud contains a high frequency of negative words like “rude”, “disappointed”, “bland”, “horrible” and “never”. It even has the word “manager” suggesting that the customer went ahead and expressed their dissatisfaction to the manager. The word “refund” suggests that the customer felt like their meal was not worth paying for.
- In contrast, the 5-star cloud has words like “great”, “amazing”, “delicious”, “recommend”, “happy”, “fresh” and “good”. These are words that one would expect to be present in positive reviews written by a happy customer.
Conclusion
On comparing the test errors for the latent factor model, we observe that there is a decrease when adding the factor of friends into the model. This validates our assumption that a user will have influences from their friends when rating a restaurant, making our rating predictor model more accurate. In terms of review generation, we observe that GPT-2 adapts to the style of reviews and accurately captures what constitutes a restaurant review. The reviews generated are realistic, coherent and well-suited for the purpose of offering customised restaurant recommendations to the user. By combining the two machine learning models, we can provide a user with the simulated experience of going to a restaurant and giving a rating and review for the restaurant based on their preference. The user can now decide with greater certainty whether or not to visit a certain restaurant given the probable outcome of going there.
Future Work
- Rating prediction can be extended further by explicitly adding features related to each restaurant, such as meal time, location and cuisine.
- Linear regression can be made more accurate by using a deep neural network instead of latent variable factorization with vanilla gradient descent.
- Review generation can be extended by taking into account the menu and cuisine of the restaurant while generating reviews so that reviews can capture details of menu-specific items.
- Review generation has potential applications in fake-review detection. The same language model can be used to compare similarity between a review and generated reviews to check whether it is real or fake.
Contributions
- Kalyani Jagdale: Preprocessing, latent factor model for rating prediction with cross validation, visualisation and website content.
- Malarvizhi Vasudevan: Comparing language models, implementing GPT-2, visualisation and website content.
- Monica Gupta: Implementing GPT-2, visualisation, website content and website design.
- Sahith Dambekodi: Latent factor model for rating prediction with cross validation, visualisation and website content.
- Tanvi Bhagwat: Preprocessing, implementing GPT-2, visualisation and website content.
Dataset source
Yelp DatasetReferences
- Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever, “Language Models are Unsupervised Multitask Learners”, OpenAI Blog, 2019
- Y. Koren and R. Bell, "Advances in collaborative filtering", Recommender Systems Handbook, Springer, 2011
- McAuley, Julian and Leskovec, Jure, "Hidden factors and hidden topics: understanding rating dimensions with review text", RecSys, ACM, 2013
- Telikani, Akbar, and Asadollah Shahbahrami, "Data Sanitization in Association Rule Mining: An Analytical Review", Expert Systems With Applications, 2018
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin, “Attention is all you need”, Advances in Neural Information Processing Systems, 2017
- He, J., & Chu, W. W., “A social network-based recommender system”, (SNRS) Springer US, 2010
- Yang, S. H., Long, B., Smola, A., Sadagopan, N., Zheng, Z., & Zha, H., “Like like alike: joint friendship and interest propagation in social networks”, Proceedings of the 20th international conference on World wide web, ACM, 2011
- minimaxir: gpt-2-simple
- The Illustrated GPT-2: Visualizing Transformer Language Models
- XLNet speaks. Comparison with GPT-2
- rusiaaman: XLnet-gen